Hello :) Today is Day 68!
A quick summary of today:
- Covered chapter 4 of Build a LLM from scratch by Sebastian Raschka
Below is an overview of the content with not much code. For the full code version of every step - it is on this github repo.
This chapter is the 3rd and final step from the 1st state towards a LLM

4.1 Coding a LLM architecture

The book will build the smallest version of GPT-2 that has 124m parameters, with the below config.

The final architecture is a combination of a few steps, presented below

After creating and initializing the model, and the gpt-2 tokenizer, on a batch of 2 sentences: ‘Every effort moves you’ and ‘Every day holds a’, the output is:

4.2 Normalizing activations with layer normalization

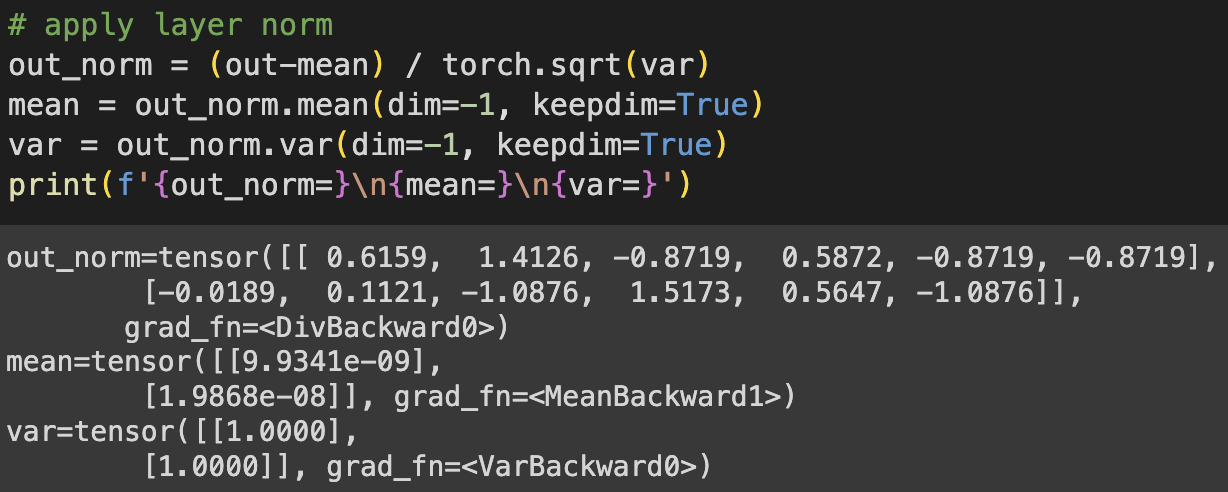
Taking an example without layer norm

The mean and var are

Apply layer norm, and the data has 0 mean and unit variance.
We can put the code in a proper class to be used later for the GPT model

4.3 Implementing a feed forward network with GELU activations
ReLU is a versatile activation function due to its simplicity and effectiveness is various NN architectures. But in LLMs, several others are used, including GELU (Gaussian Error Linear Unit) and SwiGLU (Sigmoid-Weighted Linear Unit). These 2 are a bit more complex and incorporate Gaussian and sigmoid-gated linear units, respectively.
GELU’s exact formula is GELU(x)=x⋅Φ(x), where Φ(x) is the cumulative distribution function of the standard Gaussian distribution, but in practice and in the original GPT-2 model, the below approx was used

GELU vs ReLU

Compared to ReLU, GELU is a smooth, non-linear function but with a non-zero gradient for negative values. This smoothness around the 0 (unlike ReLU) can lead to better optimization during training, as it allows for more nuanced adjustments to the model’s parameters and neurons that get negative values can still contribute to learning.
Using the GELU, we can then create the feed forward (FF) net.

In code:

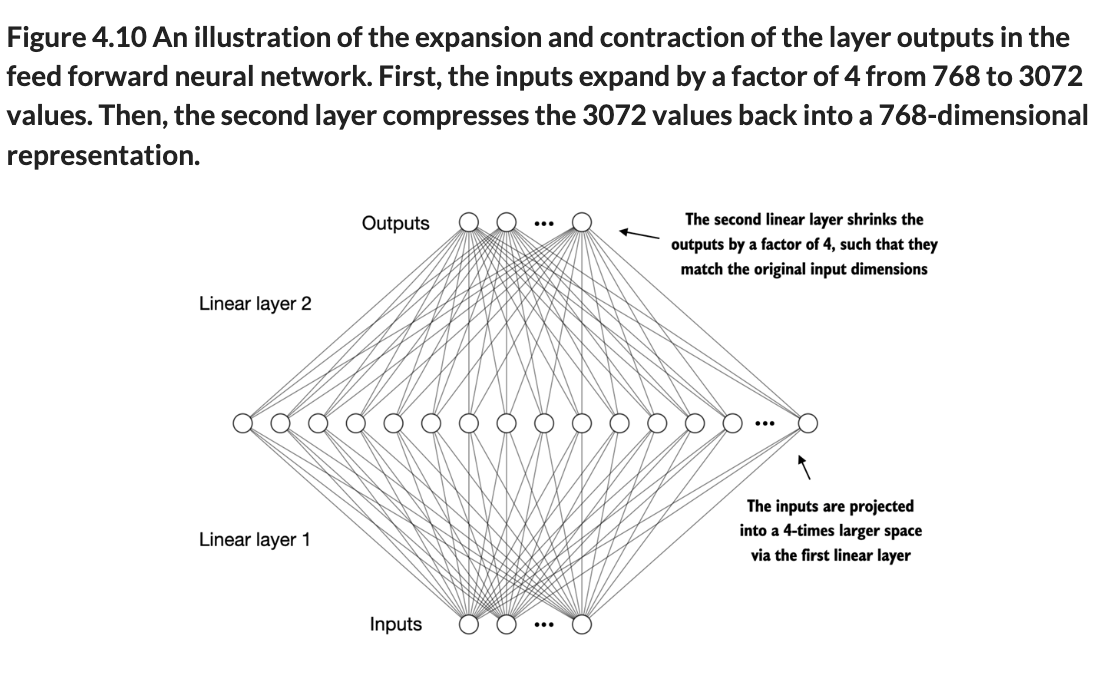
The FF net is important to allow the model the learn our data better, because first we expand the input dims by a factor of 4, pass them through GELU, and then squash them back to the original, after the model learned new info about our data.
Quick check on what we have done so far:

4.4 Adding shortcut (residual) connections
A residual connection creates an easier path for the gradient to flow through the network by skipping layer/s. This is achieved by adding the output of one layer to the output of a later layer.

If we create a model without residual connections like on the left of the graph, if we see the weights of the layers, we can clearly see the vanishing gradient problem.

However, if we add skip connections, the gradients still get smaller, but they stabilize.

Now that we have figured out multi-head attention (yesterday’s post and chapter), layer norm, GELU, FF network, residual connections figured out, we can combine them into a transformer block.
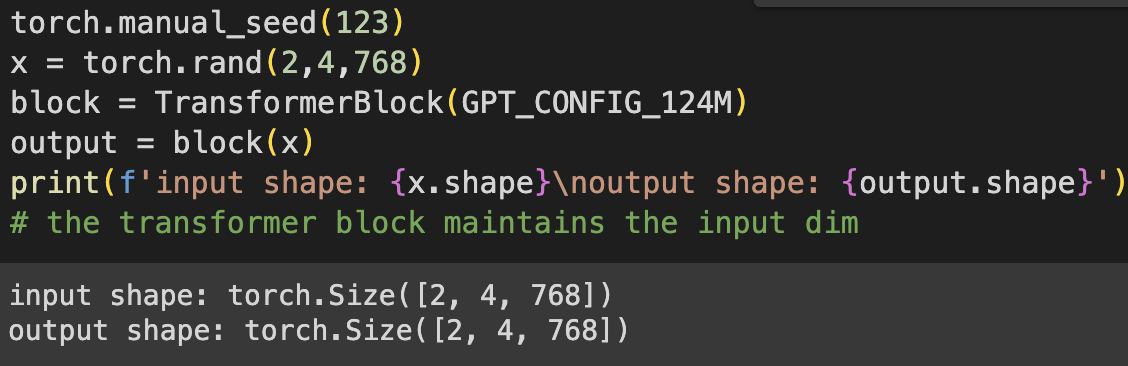
4.5 Connecting attention and linear layers in a transformer block

When a transformer block is processing an input sequence, each element (word/subword token) is represented as a x-dim vector (in GPT-2 case 768 dimensions). The magic that happens inside is that the self-attention mechanism in the multi-head attention block recognises and learns the relationships between elements of a sequence. Then the FF net learns deeper, more abstract information about the input.
In code:


4.6 Coding the GPT model
At the start of this chapter we had a dummy GPT model, empty TransformerBlock and LayerNorm


But now we can plug in the code developed throughout and get a proper GPTModel:

Using this we can compare the params of each model and its memory requirements

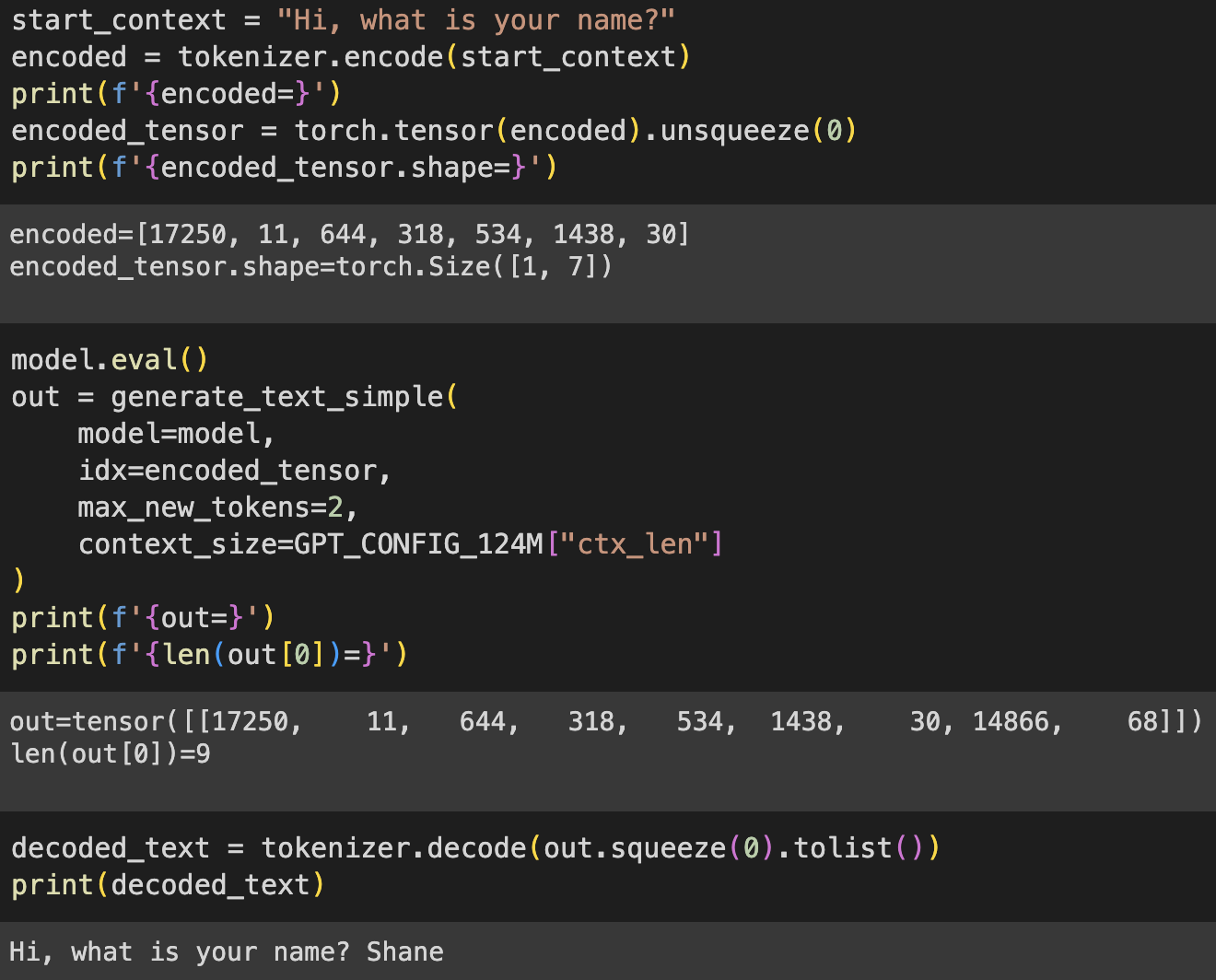
4.7 Generating text
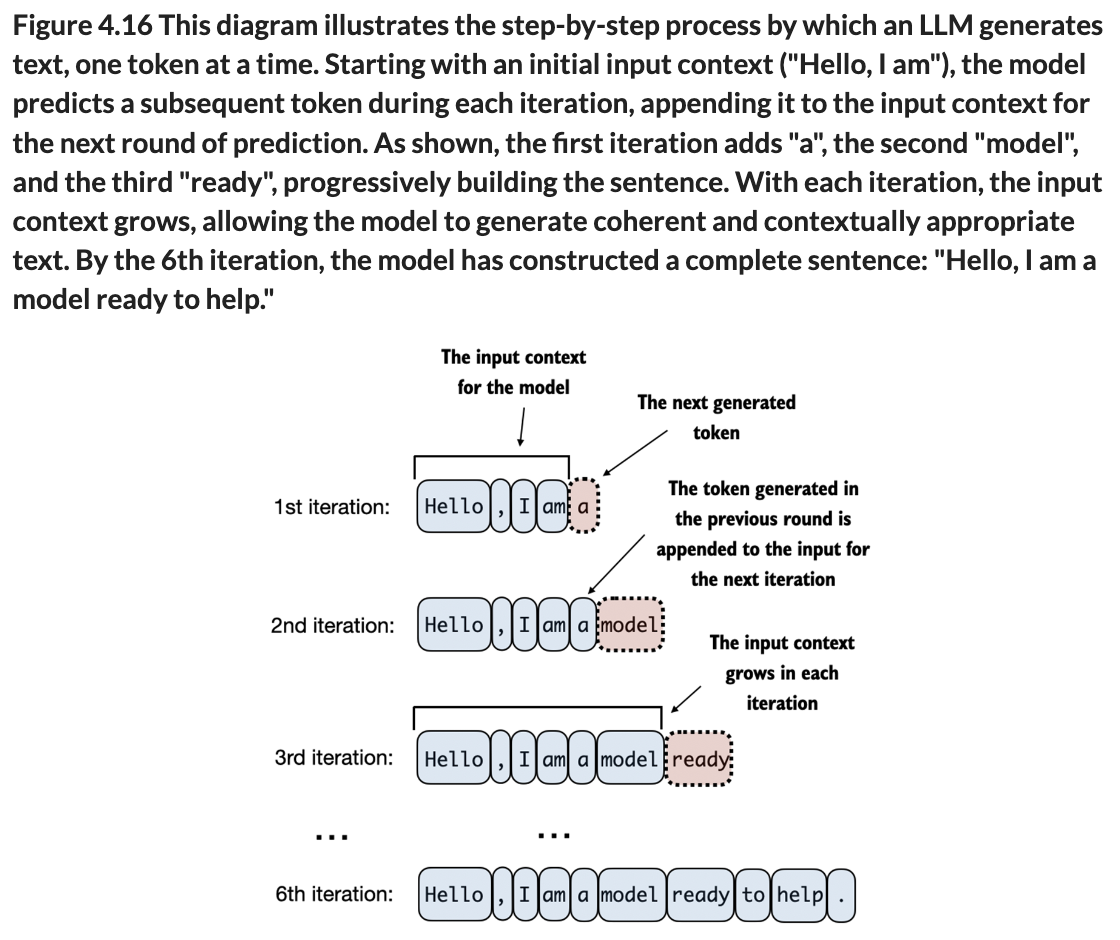
The generation of text involves multiple steps - decoding the output tensors, choosing tokens based on probability and transforming these tokens to normal text that we can read.

Example generation, given ‘Hi, what is your name?’, we get back ‘ Shane’ (with space), but most often than not, we get nonsense. like in the 2nd pic. because the model has not been trained.

At the time of writing this, the book finishes at this point. Tomorrow, I will test the whole architecture, from chapter 2 - tokenizer + dataset creation, to now - the GPTModel, and make a training loop, and use a dataset. Now I saw there are Elon Musk tweet text datasets and Harry Potter. But we will see tomorrow :)
That is all for today!
See you tomorrow :)