Hello :) Today is Day 67!
A quick summary of today:
- Covered chapter 3 of Build a LLM from scratch by Sebastian Raschka
Below are just notes with general overview, but the bigger part - with all the code implementations, developing each self-attention part from scratch is on my github repo. I uploaded yesterday’s chapter’s content too as well.
In this chapter, the attention mechanism is explored in depth.

Attention can be split into 4 parts that build on each other.

3.1 The problem with modeling long sequences
Imagine we want to develop a machine translation model - in different languages word order might be different (even if it follows the same verb object subject format). When translating we would want our model to see words that appear earlier/later, and not translate word by word because that might result in something incorrect.

Before Transformers, there were RNNs but the problem with them was that before the info is passed to the decoder, all that information is stored in the final hidden state of the encoder. After each token in a sentence the hidden state is computed sequentially, and by the time we get to the end, some of the information from the start might have been lost (RNNs have a struggle with capturing long-distance dependencies). To solve this problem, attention was designed.
3.2 Capturing data dependencies with attention mechanisms
In 2014, a Bahdanau attention was developed to help RNNs to selectively access different parts of the input at each decoding step. Below is a general idea of how attention works:
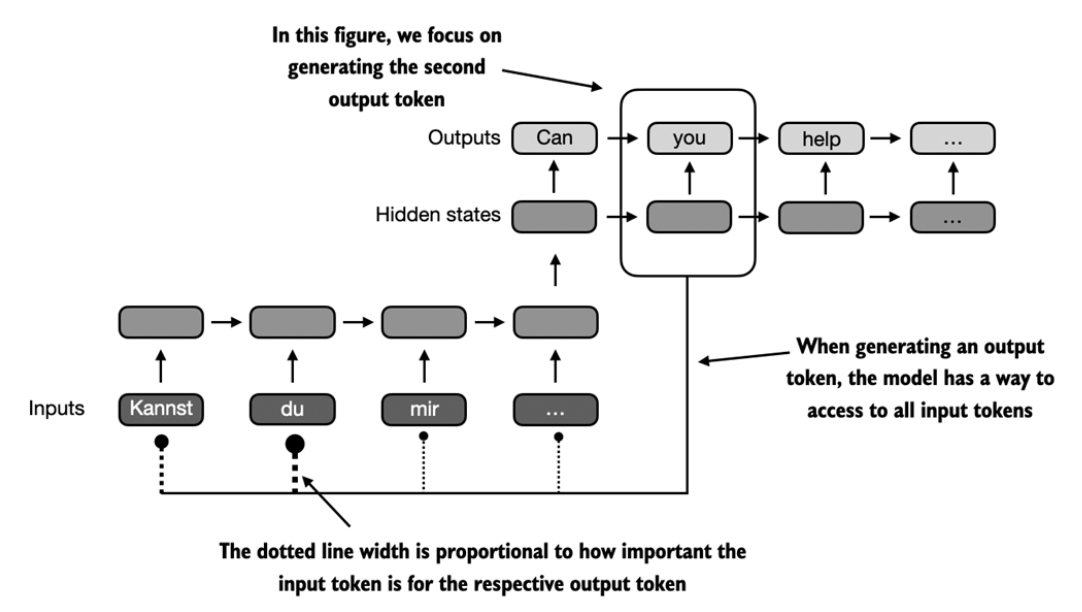
Three years later, the original transformer architecture that uses self-attention was proposed. Self-attention allows each token in the input to attend to all other positions in the input when computing the representation for that particular sequence.
3.3 Attending to different parts of the input with self-attention
The traditional attention focuses on relationships between elements of 2 sequences, like in seq2seq where the attention might be between an input and output sequence.
However, the self-attention mechanism refers to its ability to compute attention weights by learning the relationship between different positions within a single input. This allows the model to determine the importance of each token in the input sequence w.r.t. every other token in the same sequence.

3.4 Implementing self-attention with trainable weights
The self-attention used in GPT models and other popular LLMs is called scaled dot-product attention. This is the second step in the self-attention map.
The biggest difference is that here, weight matrices are introduced that are updated in training time, and are crucial for the model to learn to produce good context vectors.
In code:

3.5 Hiding future words with causal attention
The next step in achieving the self-attention used in GPT-like models is to create a causal attention machanism (a special form of self-attention). This is also known as masked attention, where while processing the current token, the model can see only previous and current inputs from a sequence (stopping it from seeing the future).

This is the 3rd step in the self-attention path:

In code:

3.6 Extending single-head attention to multi-head attention
Extending the previously developed causal attention to multiple heads. ‘Multi-head’ refers to dividing the model’s attention into multiple heads, each performing ‘magic’ independently. The main idea is to run multiple attentions in parallel, using different linear projections, and each head learning different aspects of our data.
Idea:

Execution (2 pics):

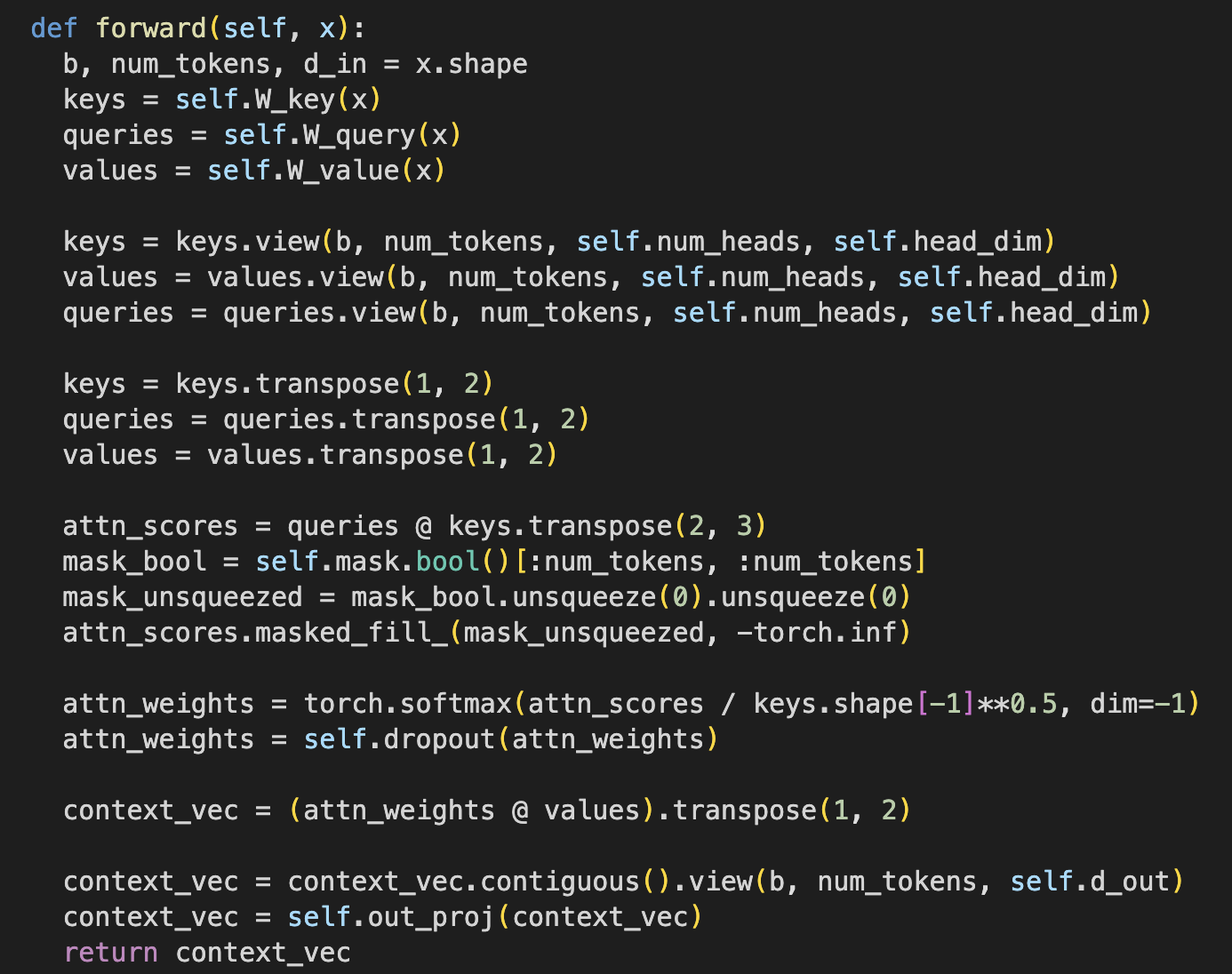
Creating the GPT-2 multi head attention with this class:

The resulting params count is 2.36m, but the GPT-2 model has 117m, which means that most of the parameters come from some other place ~ (we will see later)
That is all for today!
See you tomorrow :)