Hello :) Today is Day 116!
A quick summary of today:
- read 4 research papers about graphs and LLMs
- started transferring blog posts to the new blog UI
Do Transformers Really Perform Bad for Graph Representation? (link)
Transformers dominate the field, but so far they have not been able to break into graph representation learning. The paper presents the ‘Graphormer’ which introduces several novel ideas with its architecture.

To better encode graph structural information, below are the 3 main ideas
- Centrality encoding
- In the original transformer, the attention distribution is calculated based on semantic correlation between nodes, which ignores node importance (like a highly followed celebrity node is very important and can easily affect a social network). The centrality encoding assigns each node 2 real-valued embedding vectors according to indegree and outdegree, and this way the model can capture both semantic correlation and node importance in its attention mechanism.
- Spatial encoding
- Transformers are infamously powerful when it comes to sequential data, but in a graph - nodes are not arranged in a sequence. To give the model some info about the graph’s structure, the paper proposes spatial encoding. By providing spatial info about each node pair, the model can better learn the graph’s structure.
- Edge encoding in the attention
- Along with nodes, edges can play a key part in understanding a graph’s udnerlying structure. They propose to add to the attention mechanism a term which incorporates edge features, enhancing the model’s ability to capture the relationships between nodes more effectively. This method involves considering the edges connecting node pairs when estimating correlations, as opposed to solely relying on node features.
Implementation details
- Graphormer layer - building upon the classic transformer encoder, they apply layer norm before the multi-head self-attention, and the FF blocks.

- Special node - they introduce this special(VNode) which is connected to each individual node. Its representation is updated as normal, and in the last layer, the representation of the entire graph, would be the node feature of itself (VNode). By incorporating this special node into the Graphormer, the model gains access to global information about the graph, which can improve its performance in tasks such as graph classification, node classification, and graph generation.
Results after experiments
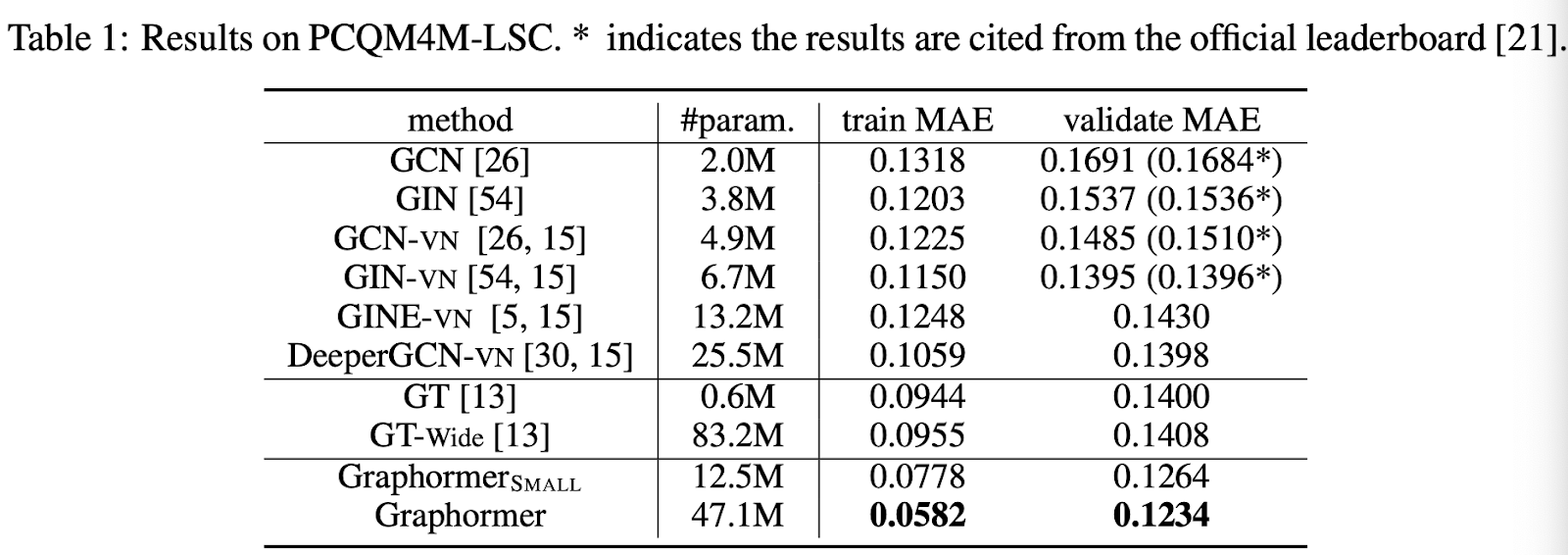
Results on Graphormer’s graph representation skills

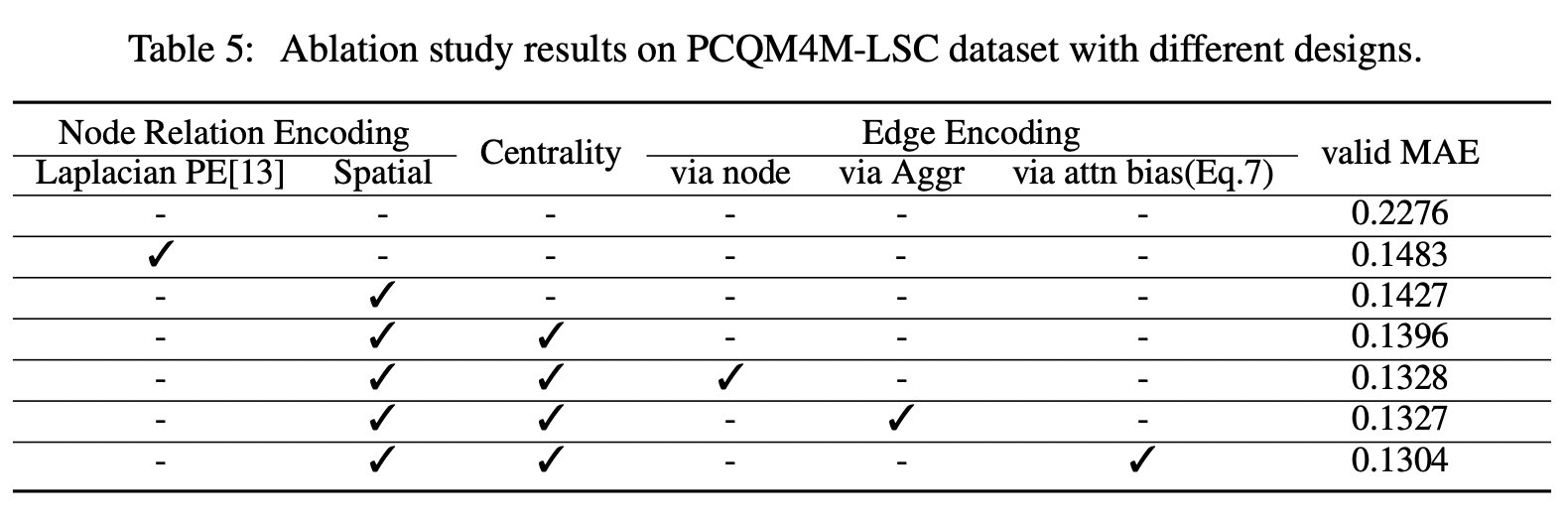
Ablation study to see effects of different parts of the Graphormer
Position-aware GNNs (link)
I covered this topic on Day 111 so there was not much new things.
Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention (link)
Infini-attention is introduced in this paper - a novel attention mechanism designed to address the limitations of standard Transformers when handling extremely long input sequences.
Traditional Transformer models struggle with long sequences due to the quadratic complexity of the attention mechanism in terms of memory and computation and this makes them inefficient for tasks requiring long-range context understanding. Infini-attention introduces some novel ideas that help battle this limitation:
-
Compressive memory - it stores and retrieves information efficiently, unlike the standard attention mechanism which discards previous states. This allows the model to maintain a history of context without exorbitant memory costs.
-
Mixed kind-of attention - combines local attention for fine-grained context within a segment and long-term linear attention using the compressive memory for global context across segments.
-
Learnable gating - which allows to learn an optimal balance between local and global context
Benefits:
-
Scalability - Infini-Transformers can handle infinitely long contexts with bounded memory and computation, enabling efficient processing of long sequences in a streaming fashion.
-
Efficiency - Compared to other long-context models, Infini-Transformers achieve significant memory compression while maintaining or improving performance.
-
Plug-and-play - the mechanism can be easily integrated into existing LLMs through continual pre-training and fine-tuning.
OpenELM: An Efficient Language Model Family with Open-source Training and Inference Framework (link)
Breaking away from past approaches that not always offer model weights and inference code, and rely on private datasets for pre-training, Apple’s release includes the entire framework for training and assessing the language model using publicly accessible datasets. This includes training logs, various checkpoints, and pre-training configurations. (wow) At the core of the released models is layer-wise scaling which allows for more fficient parameter usage. Considering a standard transformer layer, they introduce alpha and beta hyperparams that allow to scale the attention heads, and width of FFN layers, respectively. It is awesome that such a big player in the AI game, releases the full cycle of the developed models.
Comparison of OpenELM vs public comparable-sized LLMs

Also, I started transferring my blog posts to the new blog. It is a bit tidious at the start because I have to translate them, and cannot just copy-paste. Tonight I only did the first 13 days (out of ~35 days written in Korean)
That is all for today!
See you tomorrow :)